I loaded the dataset and applied NLP preprocessing steps such as tokenization, cleaning, and normalization.
CodeML Hackathon: Developing AI Models to Classify Product Feedback
- Featured
- AI

Introduction
What was this project about?
This project was developed during CodeML Hackathon 2020, a 48-hour hackathon organized by PolyAI. The challenge was to predict whether product feedback was positive or negative.
My Role
I led the development of the machine learning pipeline, including data preprocessing, text feature extraction, baseline model training, and experimentation with pre-trained language models.
Technical Details
Machine Learning: Python, Scikit-learn
Dataset: Product feedback comments (text) labeled as positive or negative.
Timeline
CodeML Hackathon, 2020
Links
TL;DR
Problem
Companies receive large amounts of product feedback that are difficult to classify manually.
Could an AI model predict if a new product comment is positive or negative?
Solution
I built machine learning models to classify product feedback as positive or negative.
- I created a baseline model with TF-IDF features and Logistic Regression.
- I implemented and tuned a Google ELECTRA model using SimpleTransformers.
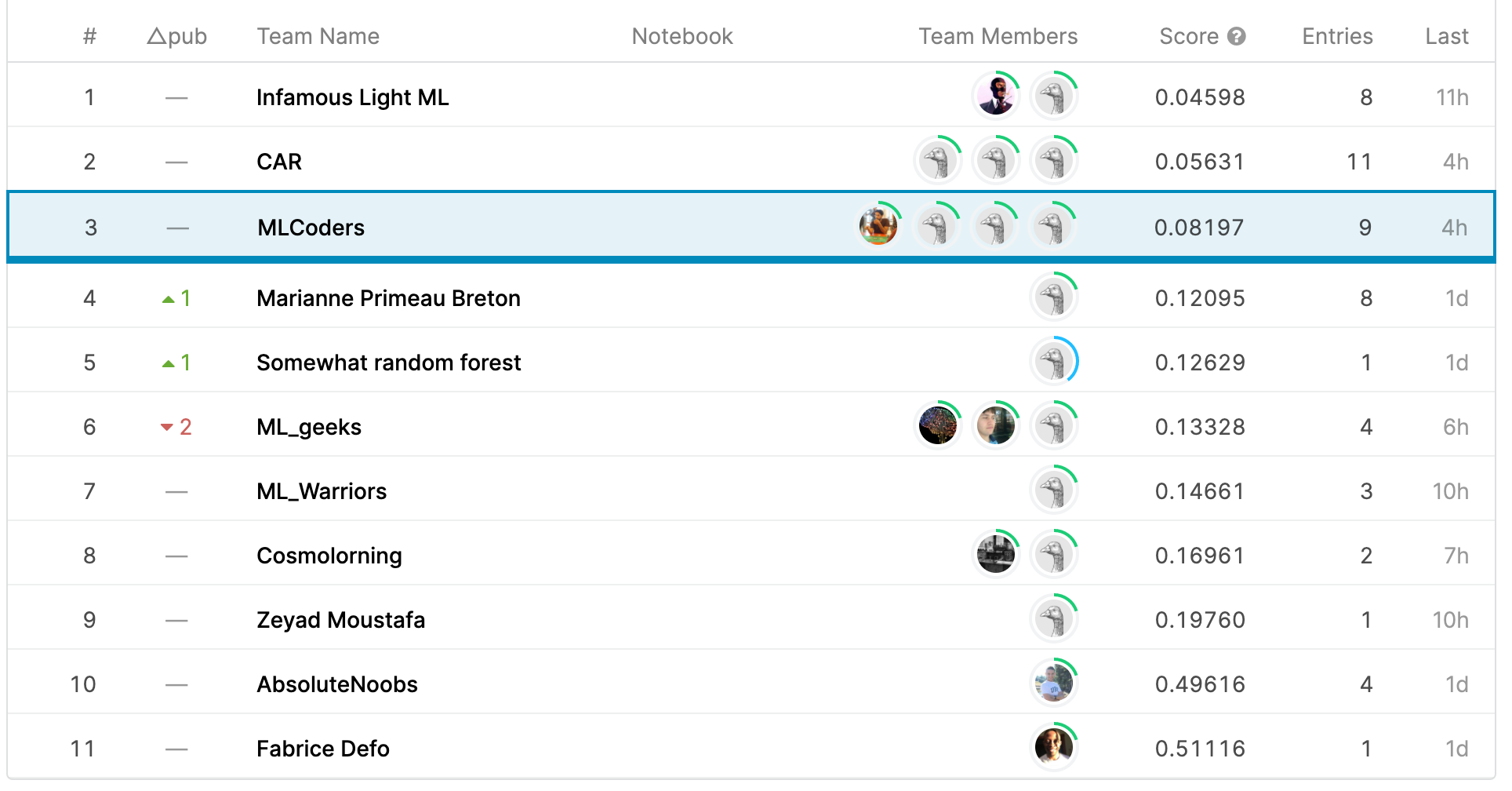
- The ELECTRA-based model reached 3rd place on the Kaggle leaderboard for the challenge.
information
Process
I transformed the comments into TF-IDF features and trained a Logistic Regression model as a first baseline for positive vs. negative feedback classification.
I then implemented a second version using Google ELECTRA through the SimpleTransformers library and tuned the model to improve performance.
I submitted my predictions and compared my performance on the Kaggle leaderboard, where my ELECTRA-based approach ranked 3rd for the sentiment classification challenge.
Impact
3rd place
Our ELECTRA-based model reached 3rd place on the Kaggle leaderboard for the sentiment classification challenge.
ELECTRA model
The project gave me hands-on experience with a pre-trained language model and showed how it could outperform a simpler baseline.